")
")

The US criminal legal system uses predictive algorithms to try to make the judicial process less biased. But there’s a deeper problem.
As a child, you develop a sense of what “fairness” means. It’s a concept that you learn early on as you come to terms with the world around you. Something either feels fair or it doesn’t.
But increasingly, algorithms have begun to arbitrate fairness for us. They decide who sees housing ads, who gets hired or fired, and even who gets sent to jail. Consequently, the people who create them—software engineers—are being asked to articulate what it means to be fair in their code. This is why regulators around the world are now grappling with a question: How can you mathematically quantify fairness?
This story attempts to offer an answer. And to do so, we need your help. We’re going to walk through a real algorithm, one used to decide who gets sent to jail, and ask you to tweak its various parameters to make its outcomes more fair. (Don’t worry—this won’t involve looking at code!)
The algorithm we’re examining is known as COMPAS, and it’s one of several different “risk assessment” tools used in the US criminal legal system.
At a high level, COMPAS is supposed to help judges determine whether a defendant should be kept in jail or be allowed out while awaiting trial. It trains on historical defendant data to find correlations between factors like someone’s age and history with the criminal legal system, and whether or not the person was rearrested. It then uses the correlations to predict the likelihood that a defendant will be arrested for a new crime during the trial-waiting period [1].
This prediction is known as the defendant’s “risk score,” and it’s meant as a recommendation: “high risk” defendants should be jailed to prevent them from causing potential harm to society; “low risk” defendants should be released before their trial. (In reality, judges don’t always follow these recommendations, but the risk assessments remain influential.)
Proponents of risk assessment tools argue that they make the criminal legal system more fair. They replace judges’ intuition and bias—in particular, racial bias—with a seemingly more “objective” evaluation. They also can replace the practice of posting bail in the US, which requires defendants to pay a sum of money for their release. Bail discriminates against poor Americans and disproportionately affects black defendants, who are overrepresented in the criminal legal system.
As required by law, COMPAS doesn’t include race in calculating its risk scores. In 2016, however, a ProPublica investigation argued that the tool was still biased against blacks. ProPublica found that among defendants who were never rearrested, black defendants were twice as likely as white ones to have been labeled high-risk by COMPAS [2].
So our task now is to try to make COMPAS better. Ready?
Let’s start with the same data set that ProPublica used in its analysis. It includes every defendant scored by the COMPAS algorithm in Broward County, Florida, from 2013 to 2014. In total, that’s over 7,200 profiles with each person’s name, age, race, and COMPAS risk score, noting whether the person was ultimately rearrested either after being released or jailed pre-trial.
To make the data easier to visualize, we’ve randomly sampled 500 black and white defendants from the full set.
We’ve represented each defendant as a dot.

Remember: all these dots are people accused (but not convicted) of a crime. Some will be jailed pre-trial; others will be released immediately. Some will go on to get rearrested after their release; others will not. We want to compare two things: the predictions (which defendants received “high” vs. “low” risk scores) and the real-world outcomes (which defendants actually got rearrested after being released).
COMPAS scores defendants on a scale of 1 to 10, where 1 roughly corresponds to a 10% chance of rearrest, 2 to 20%, and so on.
Let’s look at how COMPAS scored everyone.
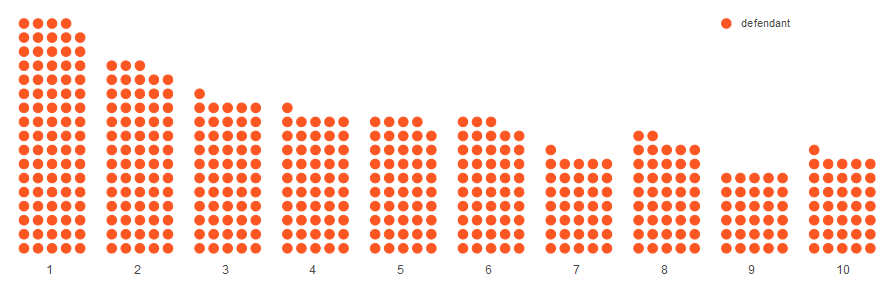
Though COMPAS can only offer a statistical probability that a defendant will be rearrested pre-trial, judges, of course, have to make an all-or-nothing decision: whether to release or detain the defendant. For the purposes of this story, we are going to use COMPAS’s “high risk” threshold, a score of 7 or higher, to represent a recommendation that a defendant be detained [3].
From here on out, you are in charge. Your mission is to redesign the last stage of this algorithm by finding a fairer place to set the “high risk” threshold.
This is what your threshold will look like.
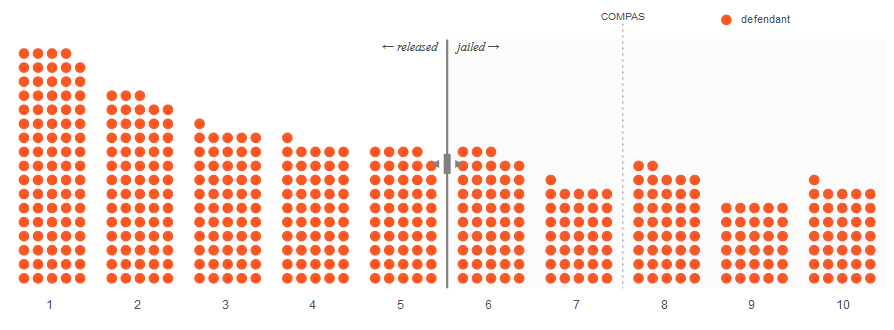
So first, let’s imagine the best-case scenario: all the defendants your algorithm labels with a high risk score go on to get rearrested, and all defendants who get a low risk score do not. Below, our graphic depicts what this might look like. The filled-in circles are defendants who were rearrested; the empty circles are those who weren’t.
Now move the threshold to make your algorithm as fair as possible.
(In other words, only rearrested defendants should be jailed.)
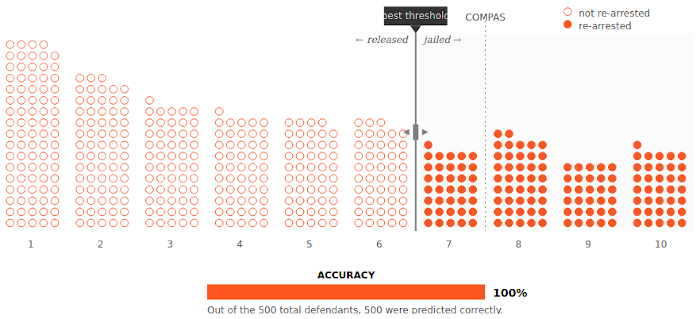
Great! That was easy. Your threshold should be set between 6 and 7. No one was needlessly detained, and no one who was released was then rearrested.
But of course, this ideal scenario never actually happens. It’s impossible to perfectly predict the outcome for each person. This means the filled and empty dots can’t be so neatly separated.
So here’s who actually gets rearrested.
Now move the threshold again to make your algorithm as fair as possible.
(Hint: you want to maximize its accuracy.)
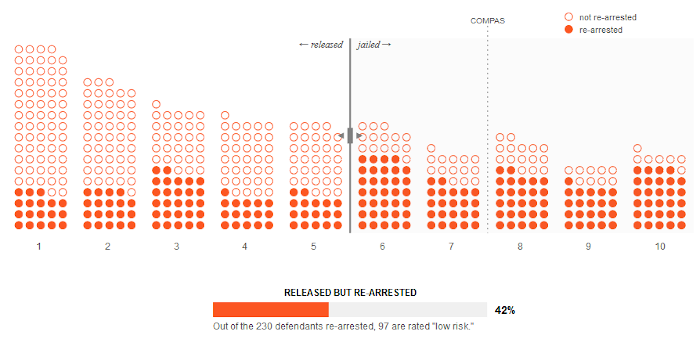
You’ll notice that no matter where you place the threshold, it’s never perfect: we always jail some defendants who don’t get rearrested (empty dots to the right of the threshold) and release some defendants who do get rearrested (filled dots to the left of threshold). This is a trade-off that our criminal legal system has always dealt with, and it’s no different when we use an algorithm.
To make these trade-offs more clear, let’s see the percentage of incorrect predictions COMPAS makes on each side of the threshold, instead of just measuring the overall accuracy. Now we will be able to explicitly see whether our threshold favors needlessly keeping people in jail or releasing people who are then rearrested.4 Notice that COMPAS’s default threshold favors the latter.
How should we fairly balance this trade-off? There’s no universal answer, but in the 1760s, the English judge William Blackstone wrote, “It is better that ten guilty persons escape than that one innocent suffer.”
Blackstone’s ratio is still highly influential in the US today. So let’s use it for inspiration.
Move the threshold to where the “released but rearrested” percentage is roughly 10 times the “needlessly jailed” percentage.
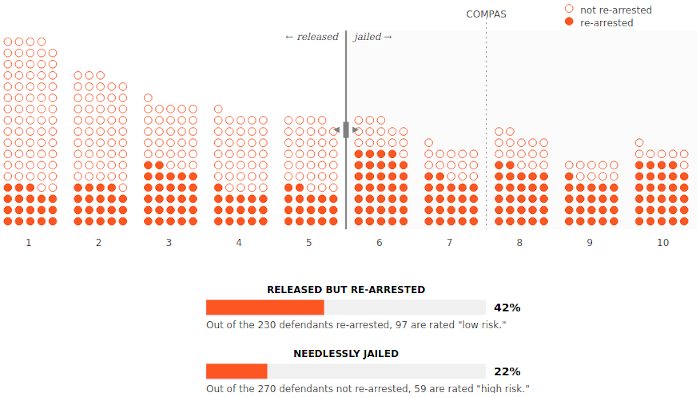
You can already see two problems with using an algorithm like COMPAS. The first is that better prediction can always help reduce error rates across the board, but it can never eliminate them entirely. No matter how much data we collect, two people who look the same to the algorithm can always end up making different choices.
The second problem is that even if you follow COMPAS’s recommendations consistently, someone—a human—has to first decide where the “high risk” threshold should lie, whether by using Blackstone’s ratio or something else. That depends on all kinds of considerations—political, economic, and social.
Now we’ll come to a third problem. This is where our explorations of fairness start to get interesting. How do the error rates compare across different groups? Are there certain types of people who are more likely to get needlessly detained?
Let’s see what our data looks like when we consider the defendants’ race.
Now move each threshold to see how it affects black and white defendants differently.
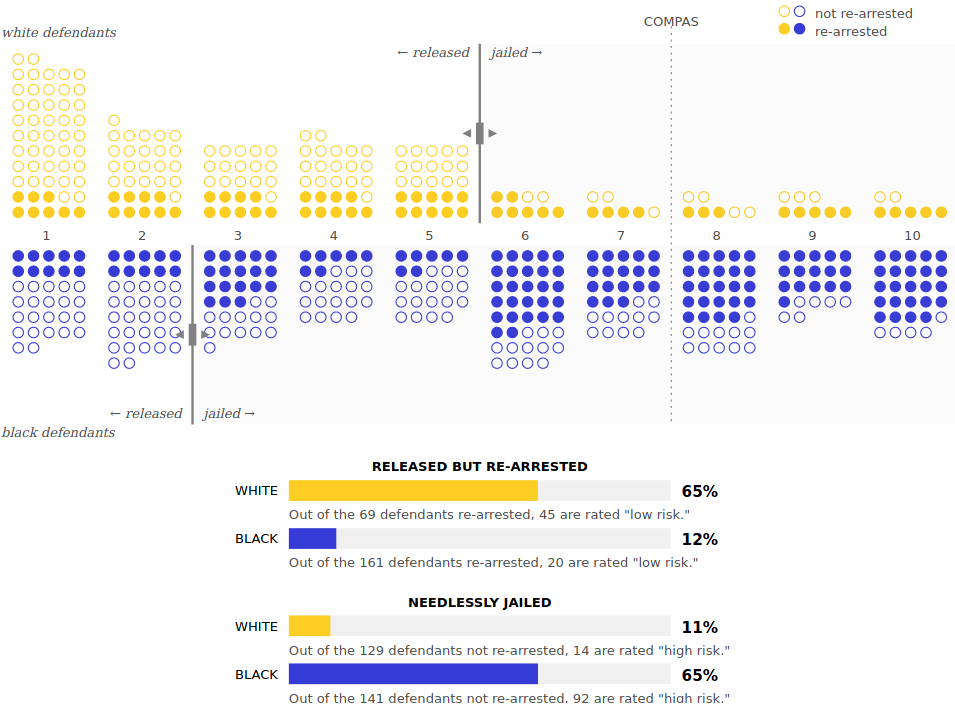
Race is an example of a protected class in the US, which means discrimination on that basis is illegal. Other protected classes include gender, age, and disability.
Now that we’ve separated black and white defendants, we’ve discovered that even though race isn’t used to calculate the COMPAS risk scores, the scores have different error rates for the two groups. At the default COMPAS threshold between 7 and 8, 16% of black defendants who don’t get rearrested have been needlessly jailed, while the same is true for only 7% of white defendants. That doesn’t seem fair at all! This is exactly what ProPublica highlighted in its investigation.
Okay, so let’s fix this.
Move each threshold so white and black defendants are needlessly jailed at roughly the same rate.
(There are a number of solutions. We’ve picked one, but you can try to find others.)
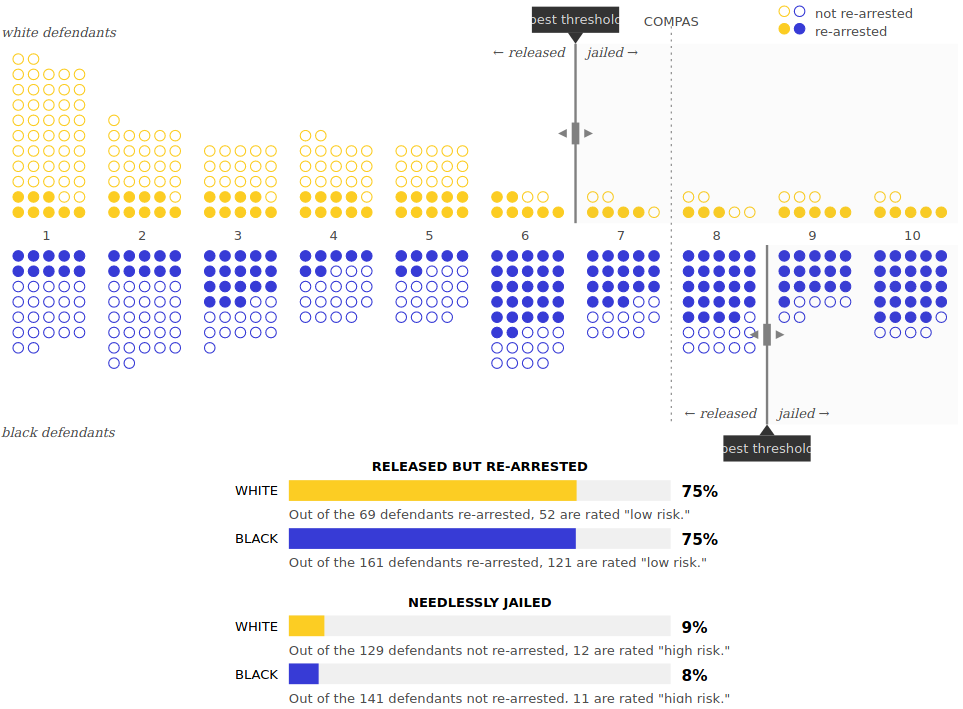
We tried to reach Blackstone’s ratio again, so we arrived at the following solution: white defendants have a threshold between 6 and 7, while black defendants have a threshold between 8 and 9. Now roughly 9% of both black and white defendants who don’t get rearrested are needlessly jailed, while 75% of those who do are rearrested after spending no time in jail. Good work! Your algorithm seems much fairer than COMPAS now.
But wait—is it? In the process of matching the error rates between races, we lost something important: our thresholds for each group are in different places, so our risk scores mean different things for white and black defendants.
White defendants get jailed for a risk score of 7, but black defendants get released for the same score. This, once again, doesn’t seem fair. Two people with the same risk score have the same probability of being rearrested, so shouldn’t they receive the same treatment? In the US, using different thresholds for different races may also raise complicated legal issues with the 14th Amendment, the equal protection clause of the Constitution.
So let’s try this one more time with a single threshold shared between both groups.
Move the threshold again so white and black defendants are needlessly jailed at the same rate.
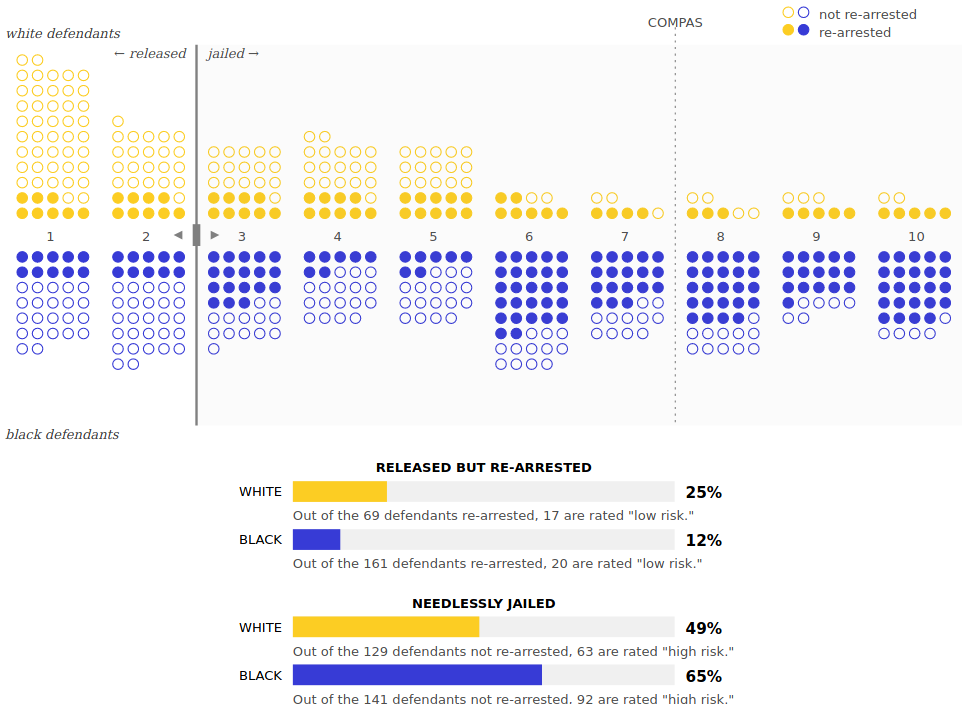
If you’re getting frustrated, there’s good reason. There is no solution.
We gave you two definitions of fairness: keep the error rates comparable between groups, and treat people with the same risk scores in the same way. Both of these definitions are totally defensible! But satisfying both at the same time is impossible.
The reason is that black and white defendants are rearrested at different rates. Whereas 52% of black defendants were rearrested in our Broward County data, only 39% of white defendants were. There’s a similar difference in many jurisdictions across the US, in part because of the country’s history of police disproportionately targeting minorities (as we previously mentioned).
Predictions reflect the data used to make them—whether by algorithm or not. If black defendants are arrested at a higher rate than white defendants in the real world, they will have a higher rate of predicted arrest as well. This means they will also have higher risk scores on average, and a larger percentage of them will be labeled high-risk—both correctly and incorrectly. This is true no matter what algorithm is used, as long as it’s designed so that each risk score means the same thing regardless of race.
This strange conflict of fairness definitions isn’t just limited to risk assessment algorithms in the criminal legal system. The same sorts of paradoxes hold true for credit scoring, insurance, and hiring algorithms. In any context where an automated decision-making system must allocate resources or punishments among multiple groups that have different outcomes, different definitions of fairness will inevitably turn out to be mutually exclusive.
There is no algorithm that can fix this; this isn’t even an algorithmic problem, really. Human judges are currently making the same sorts of forced trade-offs—and have done so throughout history.
But here’s what an algorithm has changed. Though judges may not always be transparent about how they choose between different notions of fairness, people can contest their decisions. In contrast, COMPAS, which is made by the private company Northpointe, is a trade secret that cannot be publicly reviewed or interrogated. Defendants can no longer question its outcomes, and government agencies lose the ability to scrutinize the decision-making process. There is no more public accountability.
So what should regulators do? The proposed Algorithmic Accountability Act of 2019 is an example of a good start, says Andrew Selbst, a law professor at the University of California who specializes in AI and the law. The bill, which seeks to regulate bias in automated decision-making systems, has two notable features that serve as a template for future legislation. First, it would require companies to audit their machine-learning systems for bias and discrimination in an “impact assessment.” Second, it doesn’t specify a definition of fairness.
“With an impact assessment, you're being very transparent about how you as a company are approaching the fairness question,” Selbst says. That brings public accountability back into the debate. Because “fairness means different things in different contexts,” he adds, avoiding a specific definition allows for that flexibility.
But whether algorithms should be used to arbitrate fairness in the first place is a complicated question. Machine-learning algorithms are trained on “data produced through histories of exclusion and discrimination,” writes Ruha Benjamin, an associate professor at Princeton University, in her book Race After Technology. Risk assessment tools are no different. The greater question about using them—or any algorithms used to rank people—is whether they reduce existing inequities or make them worse.
Selbst recommends proceeding with caution: “Whenever you turn philosophical notions of fairness into mathematical expressions, they lose their nuance, their flexibility, their malleability,” he says. “That’s not to say that some of the efficiencies of doing so won’t eventually be worthwhile. I just have my doubts.”
Words and code by Karen Hao and Jonathan Stray. Design advising from Emily Luong and Emily Caulfield. Editing by Niall Firth and Gideon Lichfield. Special thanks to Rashida Richardson from AI Now, Mutale Nkonde from Berkman Klein Center, and William Isaac from DeepMind for their review and consultation.
Footnotes
[1] Arrests vs. convictions: This process is highly imperfect. The tools use arrests as a proxy for crimes, but there are actually big discrepancies between the two because police have a history of disproportionately arresting racial minorities and of manipulating data. Rearrests, moreover, are often made for technical violations, such as failing to appear in court, rather than for repeat criminal activity. In this story, we oversimplify to examine what would happen if arrests corresponded to actual crimes.
[2] ProPublica’s methodology: For defendants who were jailed before trial, ProPublica looked at whether they were rearrested within two years after their release. It then used that to approximate whether the defendants would have been rearrested pre-trial had they not been jailed.
[3] COMPAS’s scores: COMPAS was designed to make aggregate predictions about groups of people who share similar characteristics, rather than predictions about specific individuals. The methodology behind its scores and the recommendations for how to use them are more complicated than we had room to present; you can read about them at the above link.
[4] Technical definitions: These two error percentages are also known as the “false negative rate” (which we’ve labeled “released but rearrested”) and “false positive rate” (which we’ve labeled “needlessly jailed”).
Source: technologyreview.com